Summary: A Clojure tutorial building a spell checker. A step-by-step guide that invites the reader to participate. Aimed at Clojure beginners, gives just enough knowledge about the language to start developing.
- Requirements
- Why a spell checker?
- How does a spell checker work?
- Implementation in Clojure
- Improvements
- Thanks for reading
- Resources
I’d like to experiment with a slightly different type of tutorial. Programming is primarily learned by doing. I’m going to describe in a step-by-step manner how to build a spell checker, but instead of just showing the solutions, questions and exercises are offered that build up to a working example.
The solutions are hidden and can be revealed by clicking on the ... click here to reveal solution ... text. That way, the reader is invited to come up with an own solution first before seeing the tutorial’s solution. I also try to not overwhelm the reader by giving just enough knowledge about Clojure to get started and answer the questions.
I’d appreciate any feedback, especially from Clojure beginners, to let me know if you found that approach useful or not.
Requirements
Leiningen1 installed. Please follow the instructions on their website how to download and install it on your system.
A little bit of Clojure knowledge would be good. I recommend working through some of the Clojure tutorial2. It’s quite dense, but I’d say spending an hour or so is sufficient for this tutorial.
Know how to start a Clojure REPL (well, just type lein repl) and how it works. More information in the Clojure tutorial3.
Some programming knowledge. If you are an absolute beginner and don’t know the difference between a map and a list then this might be too much to start with.
Preparations before we start
Create a new project
Let’s first create our project. As we use Leiningen, this is going to be a snap.
Start-up a console and type
$lein new app clojure-spellchecker
This creates all necessary files. Change into clojure-spellchecker. During this tutorial we are going to edit only two files:
src/clojure_spellchecker/core.cljis our main Clojure file. All our coding happens hereproject.cljwill only require one change later on
We’ll also need a list of words. A google search for “list of English words” gives us some choices, for example this long (109582) list of English words. Download and put it into the resources folder. Then rename it to wordsEn.txt.
Loading core.clj into REPL
We can test our code directly in REPL. Whenever it says: “try in REPL” do following steps:
- In the
clojure-spellcheckerrun:lein repl - Load the program by entering
(load-file "src/clojure_spellchecker/core.clj"). Use cursor up/down keys for going through the command history. Every new change we do requires to load our file again (there’s another way to accomplish that but for now, this is good enough)
Executing our app
The project is already executable, type in lein run and you will be greeted with the beloved “Hello World” message. Later we are using this to run our program outside the repl.
If you don’t want to follow step-by-step the final project can be found in Github.
That’s all that is needed to get started!
Why a spell checker?
I chose to use a spell checker as an example because of several advantages:
- a (somewhat) working prototype can be developed very easily in a few lines of code.
- it is a practical application that everyone has seen before.
- the very basic solution offers a lot of room for improvement and can be extended into an almost infinitely complex piece of software.
How does a spell checker work?
I won’t risk too much if I assume that you have already seen a spell-checker work. Open your text editor of choice and look for “spell check” or just start typing a (miss-spelled) word into Google and you’ll receive a “did you mean xy” answer.
How can we implement a basic working solution? Our spell checker has to do two things:
- Check whether the typed-in word is correct.
- If not correct, offer a possible correction.
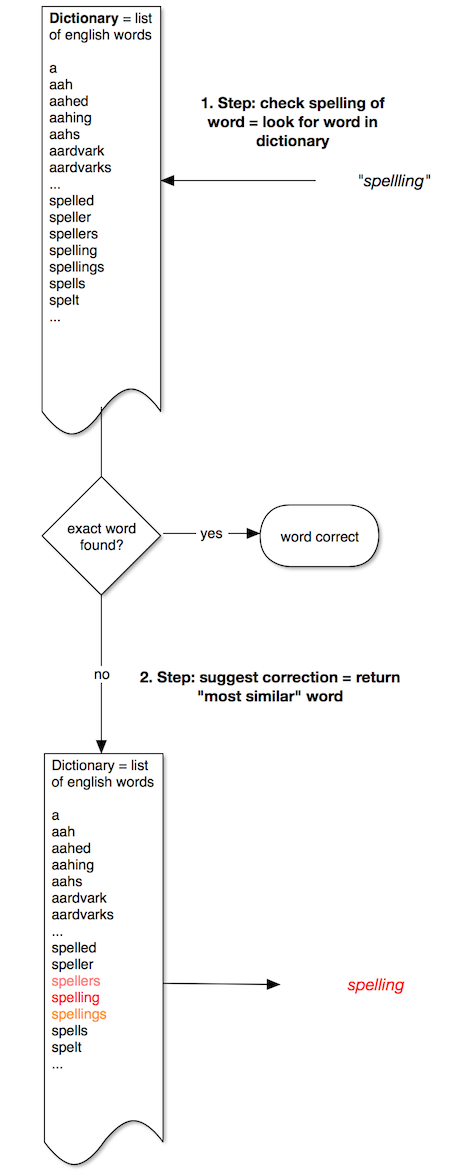
1. Check if a word is correct
The solution is simple: have a list of correct words and check whether the typed-in word can be found in that list. If yes: the word is correct, if not: it’s incorrect. We use the list we have downloaded in the preparation step above.
2. Offer a correction
If a typed-in word is not found in our list of correct words, we want to suggest a correction. The world of correct words of our spell-checker is this list. Therefore, the possible correction must come from it. What we want to do then is to find the word in the list that is “most similar” to the one the users has entered. What “similar” means is still to be discussed, but for now, let’s assume we can find that.
Taken together, our spell-checker can be depicted in this diagram:
Implementation in Clojure
1. Checking if a word is correct
First, we need to decide on the correct data structure to use. Clojure has following collections:
- List: an unordered list of items
- Vector: an ordered list of items
- Map: a collection of key/value pairs
- Set: an unordered list of unique items (no duplicates)
Question: where are going to use a set as our dictionary. Why?
testsolution
We just need a list of unique words and we don’t care about order.
Clojure set
A set is represented in Clojure with
#{elements}or
(set elements-in-a-collection)The first thing to note is that in Clojure there are often two ways to express something. There is the “pure” form, that is called prefix notation4 and looks like this:
(function-name variable-number-of-arguments)So we can define a set as:
(set ["a" "b" "c" "d"])where set is the function name and ["a" "b" "c" "d"] is one argument (which itself is a vector or array of strings).
The set function now does following: giving a collection (the vector), return a set of unique elements. In REPL:
(set ["a", "b", "c", "c"])
-> #{"a" "b" "c"}As sets are used quite often, there is a second way to express it. It’s called a reader macro and considered “syntactic sugar” as it helps the programmer to type less but is not strictly required. The REPL already uses it:
#{"a" "b" "c"} ; same as (set ["a" "b" "c"])There are many other reader macros available in Clojure. For now, don’t worry about this. I’ll introduce more along this tutorial.
Exercise: Another interesting thing happens when typing (set ["a", "b", "c", "c"]) into REPL. What is it?
testsolution
In the REPL answer: -> #{"a" "b" "c"} the duplicated "c" has disappeared. As mentioned above, the items in a set are unique and duplicates are ignored.
Implement the dictionary
Let’s start implementing. First, we need to read the word file into our program. Clojure has the slurp function for this
=> (doc slurp)
clojure.core/slurp
([f & opts])
Opens a reader on f and reads all its contents, returning a string.
See clojure.java.io/reader for a complete list of supported arguments.We can read our words file into a String in Clojure. We name it “words”. In Clojure, we name things with def.
(def symbol initial-value?)Note: the ? question mark means that it is optional (one or zero times in this case). It is possible to name something without giving it an initial value.
Exercise: Edit src/clojure_spellchecker/core.clj. Load the words files that you have copied to “resources/wordsEn.txt” into our program using slurp. Name the resulting String “words”.
testsolution
(def words
(slurp "resources/wordsEn.txt")) Print out the content in REPL:
clojure-spellchecker.core=> (load-file "src/clojure_spellchecker/core.clj")
clojure-spellchecker.core=> words
"a\r\naah\r\naahed\r\naahing\r\naahs\r\naardvark\r\naardvarks\r\naardwolf\r\nab\r\nabaci\r\naback\r\nabacus\r\nabacuses\r\nabaft\r\nabalone\r\nabalones\r\nabandon\r\nabandoned\r\nabandonedly\r\nabandonee\r\nabandoner\r\nabandoners\r\nabandoning\r\nabandonment\r\nabandonments\r\nabandons\r\ ......
We have now the correct word list combined in a huge String and separated by a newline symbol. Next, we need to transform that into a set of words. First, we split the lines. We look again into what Clojure has to offer and soon we find a function called split-lines5. However, this function is not immediately available (as set is for example). It lives in a different namespace6. In Clojure, libraries, functions, variables and so on are organized in namespaces.
We need to add the namespace of split-lines. It resides in clojure.string. We do this by using the ns macro at the beginning of our program file. Leiningen has already added it to us. Change core.clj to:
(ns clojure-spellchecker.core
(:require [clojure.string :as str]))As you can see, we can also rename the reference to cloure.string to just str. That saves typing.
We can use split-lines as follows:
(str/split-lines file))Let’s try it in the REPL.
$ lein repl
clojure-spellchecker.core=> (load-file "src/clojure_spellchecker/core.clj")
#'clojure-spellchecker.core/-main
Exercise: In the REPL, apply split-lines to words.
testsolution
clojure-spellchecker.core=> (str/split-lines words)
["a" "aah" "aahed" "aahing" "aahs" "aardvark" ....
Good. Now we have the words, but there are returned as a list as the square brackets show. But we can convert those easily into a set.
Exercise: convert the list of words that split-lines returns into a set. Functions can be combined by using the result of a function directly as the input of the next, e.g (function-a (function-b parameter))
testsolution
(def words
(set (str/split-lines (slurp "resources/wordsEn.txt"))))If we look at words in REPL, we can see that it has been converted into a set:
clojure-spellchecker.core=> (load-file "src/clojure_spellchecker/core.clj")
clojure-spellchecker.core=> words
#{"ghoulishly" "refraining" "beachboys" "debuted" "protectiveness" "carnie" "overcharging" "flightier" "premiss" "undistilled" "isometrics" "embroiders" ....
However, there is still one problem. Try to find the word “spelling” in the set. It looks like this (assuming you have downloaded the same word list file above):
... "intelligently" "bootlicker" " spelling" "wobbliest" ...
The word starts with a space which can make searching for it difficult and is ugly. What we need is a “data cleaning” step of our word file.
What we are looking for is a way to apply a cleaning function to each element of our list of words. To clean, we can use another function of the clojure.string namespace: trim
clojure-spellchecker.core=> (doc str/trim)
-------------------------
clojure.string/trim
([s])
Removes whitespace from both ends of the string.
This will solve it. But how can we apply this function to each member of our words set?
This is a fundamental process in functional programming. If you come from an imperative programming language background, you’d choose a for (....) loop. In a functional language, this can be solved much easier, with a map function:
(map f c)map will apply function f to each element of the collection c.
Exercise: Extend words the same way you have extended it before: wrap it into another function call. This time add a “cleaning” step by applying the str/trim function to each element of the words array. Add the cleaning step before calling set
testsolution
(def words
(set (map str/trim (str/split-lines (slurp "resources/wordsEn.txt")))))We can implement now a function that tests if a word is correct. We need to check if our words list contains the typed-in word of a user.
Clojure functions
So far we have only used functions. Now we create one. That is done in Clojure with defn:
(defn functionname [parameters] body)For example, Leiningen has already created a function for you. It is the main function (which gets executed by running lein run) and looks like this:
(defn -main
"I don't do a whole lot ... yet."
[& args]
(println "Hello, World!"))-mainis the function name. The minus sign indicates that this function is not visible outside of its namespace.- [& args] are the parameter names.
&is a special sign that allows the function to accept a variable length of parameters - “I don’t do a whole lot … yet.” is an optional doc string we ignore for now
(println "Hello, World!")is the body of the function.
There is (a lot) more to say about functions. The return value of a function is its last expression. In this case, it’s nothing -> nil in Clojure terms. println is not the return value but a feared “side effect” of the function: it does something that changes the environment when executed (printing words on the console in this case). Let’s rewrite “hello word” in a more simplified manner:
(defn hello-world [name]
(println "Hello," name))Type the whole function definition into REPL:
clojure-spellchecker.core=> (defn hello-world [name]
#_=> (println "Hello " name))
#'clojure-spellchecker.core/hello-world
Exercise: In the REPL, execute hello-world. What part of the REPL answer is the side effect and what the return value?
testsolution
clojure-spellchecker.core=> (hello-world "Hans")
-> Hello, Hans <== side effect
-> nil <== return value
Now that we know how to define functions, let’s implement our spell-check function.
Exercise: Go to http://java.ociweb.com/mark/clojure/article.html#Collections and look at the functions that are available for sets to find one that checks if a set contains an item. Implement then a new function called correct? that takes a word and returns true or false
testsolution
; core.clj
(ns clojure-spellchecker.core
(:require [clojure.string :as str]))
(def words
(set (map str/trim (str/split-lines (slurp "resources/wordsEn.txt")))))
(defn correct? [word] (contains? words word))In REPL we test the first step of our spell-checker
clojure-spellchecker.core=> (load-file "src/clojure_spellchecker/core.clj")
clojure-spellchecker.core=> (correct? "absolutely")
-> true
clojure-spellchecker.core=> (correct? "absolutly")
-> false
Let’s continue with the second part
2. Offer a correction
Let’s make our program first a real app by properly implementing the main method so we can execute it via lein run.
What we want to accomplish is this: if the user typed in word is correct, print “correct” to the console and if not a correction like google: “Did you mean …. ?”.
In Clojure, we have the if special form. It is called “special form” because it behaves differently than the rest of Clojure. It has the following form:
(if condition then-expr else-expr)In REPL
clojure-spellchecker.core=> (if (< 1 0)
#_=> (println "one is smaller than zero")
#_=> (println "one is not smaller than zero"))
one is not smaller than zero
nil
We want to use our spell-checker with leiningen. lein run word-to-check executes the main function handing over the arguments which are then available as args in (defn -main [& args]). args is a list of arguments. As we just give one word to check, we can read this word by using (first args).
We want to give this argument a name. Clojure allows that with another special form:
(let [variable-name-pairs] body)Example:
clojure-spellchecker.core=> (let [variable1 1 variable 2](println "variable1 is" variable1))
variable1 is 1
nil
The assignment we define with let is valid inside the body of let.
Exercise: Edit the main function of core.clj. Assign the typed-in word that the first argument of args to a new variable named word. Then, in the body of the let special form, add an if-clause that checks whether the word is correct. If it is correct, print “correct” to the console. If not, print “Did you mean xy”
testsolution
(ns clojure-spellchecker.core
(:require [clojure.string :as str]))
(def words
(set (map str/trim (str/split-lines (slurp "resources/wordsEn.txt")))))
(defn correct? [word] (contains? words word))
; the new main function
(defn -main [& args]
(let [word (first args)]
(if (correct? word)
(println "correct")
(println "Did you mean xy ?"))))With the main function in place, we can execute our app with leiningen:
$ lein run spelling
correct
$ lein run spellling
Did you mean xy ?
We can now implement the last missing piece: provide a correction.
As explained above, we want to find a word that is “most similar” to the user typed-in word. However, deciding what word is “similar” can be very difficult, if not impossible, to answer. For example, if I write “leav” did I mean “leave” or “leaf”? We could derive that by looking at the whole sentence. We could also say that the word “leave” is much more common than the word “leaf” (unless the text is about trees). The similarity of words is a difficult subject and that is where we could later greatly improve our algorithm.
For this tutorial, we start with a simple solution. A common way to determine the similarity between words is the “edit distance” (also called Levenshtein distance7). It goes like this: count the steps I need to get from word A to word B. The words “spellling” and “spelling” have the distance 1, because I need to delete one “l” to get from A to B.
So for our correction, we want to choose words of our word list that have the smallest edit distance to the typed-in word.
Implement Levenshtein distance
We don’t implement this. We re-use an external library. But looking at the Clojure libraries, we can’t find an implementation. Or we may be Java developers and know already a good implementation, which indeed exists: Apache Commons StringUtils has a LevenshteinDistance` method. In Clojure, we can easily use Java libraries.
Using Java in Clojure
As we are using a library that is not part of the core Clojure, we need to add it in two places: in the dependencies of our project, so that Leiningen will download it, and in the namespace.
Edit project.clj and change the dependencies part (you can find the whole file in Github):
(defproject clojure-spellchecker "0.1.0-SNAPSHOT"
:dependencies [[org.clojure/clojure "1.6.0"]
[org.apache.commons/commons-lang3 "3.3.2"]][org.apache.commons/commons-lang3 "3.3.2"] tells Leiningen what to download next time we run it.
Now add it to the namespace. Java dependencies are included in the ns macro with the :import keyword.
(ns clojure-spellchecker.core
(:require [clojure.string :as str])
(:import (org.apache.commons.lang3 StringUtils)))Implement distance function
Finally, we can implement a function that gives us the distance of two words.
Exercise: Implement a function called distance that takes two words and returns the Levenshtein distance of the two words. Use StringUtils
testsolution
(defn distance [word1 word2]
(StringUtils/getLevenshteinDistance word1 word2))Let’s try it in the REPL
clojure-spellchecker.core=> (load-file "src/clojure_spellchecker/core.clj")
#'clojure-spellchecker.core/-main
clojure-spellchecker.core=> (distance "spelling" "spellling")
1
clojure-spellchecker.core=> (distance "clojure" "closure")
1
clojure-spellchecker.core=> (distance "clojure" "java")
6
Works.
Final step
We need to find a word in the dictionary that has the smallest distance to the word the user has typed in.
How can we do that? We get now to the meat of our application!
A general rule for an aspiring Clojure-developer is to first check what Clojure is already offering. We go to the Clojure docs and search there. I like this Clojure cheatsheet8 that has a search box that automatically filters the results (there is also (doc-search "search-term") to search in a similar way in REPL). We are looking to minimize something so I type in “min”.
First, there is min.
clojure-spellchecker.core=> (doc min)
-------------------------
clojure.core/min
([x] [x y] [x y & more])
Returns the least of the nums.
It returns the minimum number of the supplied arguments. This does not yet do it for us. But then there is min-key
clojure-spellchecker.core=> (doc min-key)
-------------------------
clojure.core/min-key
([k x] [k x y] [k x y & more])
Returns the x for which (k x), a number, is least.
This “smells” of a solution. This takes a function k, which returns a number, and returns the minimum of (k x), k applied to the rest of the arguments. For example, return the shortest string (we use count as function k)
clojure-spellchecker.core=> (min-key count "this" "are" "some" "words")
"are"
We have still two things to figure out:
- How can we use our
distancefunction as functionk? - How can we apply
min-keyto our word list?
Use distance function inside min-key
If we try this:
clojure-spellchecker.core=> (min-key distance "spellling" words)
ArityException Wrong number of args (1) passed to: core/distance clojure.lang.AFn.throwArity (AFn.java:429)
Clojure basically tells us: “distance needs two arguments, you supplied only one”. min-key takes distance and applies it to “spelling” but not words. What we need is to have another distance function, that takes the typed-in word as a default and then min-key can take it and apply it to the words in our list.
There is a solution in Clojure: the partial function.
clojure-spellchecker.core=> (def distance-to-spelling (partial distance "spelling"))
#'clojure-spellchecker.core/distance-to-spelling
clojure-spellchecker.core=> (distance-to-spelling "spellling")
1
(partial distance "spelling") transforms (distance [word1 word2]) into something like “(distance [word1 "spelling"])”.
With the partial function of distance, we can implement a part of our solution.
Exercise: Implement a function called “min-distance” that takes a word and returns min-key of a partial distance function and (for now) just two additional words from the dictionary: “spelling” and “spilling”. In other words, fill in following: (defn min-distance[word](min-key <partial distance> "spelling" "spilling"))
testsolution
(defn min-distance [word]
(min-key (partial distance word) "spelling" "spilling"))Let’s test it using Leiningen:
$ lein run spelling
correct
$ lein run spellling
Did you mean spelling ?
$ lein run clojure
Did you mean spilling ?
It works. But of course, as our dictionary contains only two words, the last correction is not satisfying.
Applying min-key with partial distance to our word list
We need a way to apply min-key and the partial distance successively to words. The Clojure answer to this is a function called apply.
apply works similar to map on every item of a collection, but instead of mapping a function to each member of the collection separately, apply unwraps a collection and applies it to each item.
Compare in REPL:
clojure-spellchecker.core=> (apply + [1 2 3 4 5])
15
clojure-spellchecker.core=> (map (partial + 1) [1 2 3 4 5])
(2 3 4 5 6)
Don’t worry if you don’t fully grasp this now. It’s rather advanced. But we have now the right tool to finish our ‘min-distance’ function.
Exercise: Use apply to make (min-key (partial distance word) ...) work with words
testsolution
(defn min-distance [word]
(apply min-key (partial distance word) words))Try in REPL:
clojure-spellchecker.core=> (load-file "src/clojure_spellchecker/core.clj")
clojure-spellchecker.core=> (min-distance "spellling")
"spelling"
clojure-spellchecker.core=> (min-distance "spelling")
"spelling"
clojure-spellchecker.core=> (min-distance "spillling")
"spilling"
It works.
In the very last step, we use min-distance in our main function.
Exercise: Extend -main to use min-distance to suggest a correction. The solution shows the final app.
testsolution
(ns clojure-spellchecker.core
(:require [clojure.string :as str])
(:import (org.apache.commons.lang3 StringUtils)))
(def words
(set (map str/trim (str/split-lines (slurp "resources/wordsEn.txt")))))
(defn correct? [word] (contains? words word))
(defn distance [word1 word2]
(StringUtils/getLevenshteinDistance word1 word2))
(defn min-distance [word]
(apply min-key (partial distance word) words))
(defn -main [& args]
(let [word (first args)]
(if (correct? word)
(println "correct")
(println "Did you mean" (min-distance word) "?"))))That’s it, we have a working prototype:
$ lein run spelling
correct
$ lein run spellling
Did you mean spelling ?
$ lein run clojure
Did you mean cloture ?
$ lein run absolutly
Did you mean absolutely ?
It required just a few lines. Don’t you think that Clojure leads to rather compact and clean code??
Improvements
Of course, we have only implemented a rudimentary solution that can be improved on. The quality of our spell-checker greatly depends on our internal list of correct words. Improving this list would improve the “knowledge” of our app. We could, for example, try to build this list on our own. We could consume the whole Wikipedia and build a new list. That way, our word list would likely improve it’s quality.
Then there is the already discussed problem of “similarity”. One better approach than applying plain edit distance is to take probability into account. Not all words are equally important. If our spell-checker finds words of the same distance, we could choose a word that has a higher probability of occurrence in the English language. Peter Norvig wrote a great introduction9 about this (he also describes a way to test the effectiveness of the algorithm - another point we’d need to tackle).
There are more things to improve on, as performance (our app is not “production ready” yet) and more sophisticated features like grammar and other advanced natural language processing features.
I hope you found this tutorial useful. The whole Leiningen project can be found in github10.
Thanks for reading
I hope you enjoyed reading this post. If you have comments, questions or found a bug please let me know, either in the comments below or contact me directly.
Resources
-
Tutorial Clojure namespace ↩